
Page 87 - 2024年第55卷第1期
P. 87
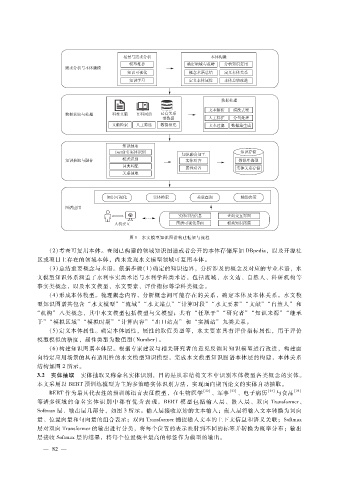
图 1 水文模型知识图谱构建框架与流程
(2)考查可复用本体。查阅已构建的领域知识图谱或者公开的本体存储库如 DBpedia,以及开源社
区或项目上存在的领域本体,尚未发现水文模型领域可复用本体。
( 3)总结重要概念与术语。依据步骤(1)确定的知识边界,分析涉及的概念及对应的专业术语,水
文模型知识体系涵盖了水利事实类术语与水利学科类术语,包括流域、水文站、自然人、科研机构等
事实类概念,以及水文模型、水文要素、评价指标等学科类概念。
(4)形成本体模型。梳理概念内容,分析概念间可能存在的关系,确定本体及本体关系。水文模
型知识图谱共包含 “水文模型” “流域” “水文站点” “计算时段” “水文要素” “文献” “自然人” 和
“机构” 八类概念,其中水文模型包括模型与父模型;共有 “任职于” “研究者” “知识来源” “继承
于” “模拟区域” “模拟时期” “计算内容” “出口站点” 和 “实测站” 九类关系。
( 5)定义本体属性。确定本体属性,属性的取值类型等,水文要素具有评价指标属性,用于评价
模型模拟的精度,属性类型为数值型( Number)。
( 6)构建知识图谱本体层。根据专家建议与相关研究者的意见反馈对知识模型进行改进,构建面
向特定应用场景的具有适用性的水文模型知识模型,完成水文模型知识图谱本体层的构建,本体关系
结构如图 2所示。
3.2 实体抽取 实体抽取又称命名实体识别,目的是从非结构文本中识别本体模型各类概念的实体。
本文采用以 BERT预训练模型为主的多策略实体识别方法,实现面向期刊论文的实体自动抽取。
BERT作为最具代表性的预训练语言表征模型,在生物医学 [22] 、军事 [23] 、电子病历 [24] 与食品 [25]
等诸多领域 的 命 名 实 体 识 别 中 都 有 优 秀 表 现。BERT模 型 包 括 输 入 层、嵌 入 层、双 向 Transformer、
Softmax层、输出层几部分,如图 3所示。输入层接收原始的文本输入;嵌入层将输入文本转换为词向
量、位置向量和句向量的组合表示;双向 Transformer捕捉输入文本的上下文信息和语义关联;Softmax
层对双向 Transformer的输出进行分类,将每个位置的表示映射到不同的标签并转换为概率分布;输出
层接收 Softmax层的结果,将每个位置概率最高的标签作为模型的输出。
— 8 2 —