
Page 43 - 2025年第56卷第9期
P. 43
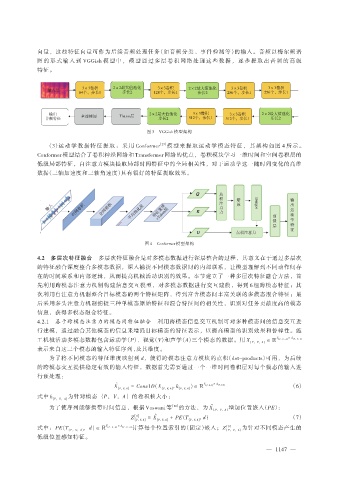
向量,这些特征向量可作为后续音频处理任务(如音频分类、事件检测等)的输入。音频以梅尔频谱
图 的 形 式 输 入 到 VGGish 模 型 中 , 模 型 通 过 多 层 卷 积 网 络 处 理 这 些 数 据 , 逐 步 提 取 出 音 频 的 高 级
特征。
图 3 VGGish 模型架构
[27]
(3)运 动 学 数 据 特 征 提 取: 采 用 Conformer 模 型 来 提 取 运 动 学 模 态 特 征, 其 架 构 如 图 4 所 示 。
Conformer 模型结合了卷积神经网络和 Transformer 网络的优点,卷积模块学习一维时间和空间卷积层的
低级局部特征,自注意力模块提取局部时间特征中的全局相关性,对于运动学这一随时间变化的高维
数据(三轴加速度和三轴角速度)具有很好的特征提取效果。
图 4 Conformer 模型架构
4.2 多层次特征融合 多层次特征融合是对多模态数据进行深层整合的过程,其意义在于通过多层次
的特征融合深度整合多模态数据,深入捕捉不同模态数据间的内部联系,让模型理解到不同动作间存
在的时间联系和内部逻辑,从而提高机械活动识别的效果。本节建立了一种多层次特征融合方法,首
先利用跨模态注意力机制构建信息交互模型,对多模态数据进行交互建模,得到 6 组跨模态特征;其
次利用自注意力机制整合目标模态的两个特征矩阵,得到富含模态间丰富关联的多模态混合特征;最
后采用多头注意力机制捕捉三种单模态原始特征和混合特征间的相关性,识别对任务贡献度高的模态
信息,获得多模态融合特征。
4.2.1 基于跨模态注意力的模态间特征融合 利用跨模态信息交互机制可对多种模态间的信息交互进
行建模,通过融合其他模态的信息来增强目标模态的特征表示,以提高模型的识别效果和鲁棒性。施
工机械活动多模态数据包含运动学(P)、视觉(V)和声学(A)三个模态的数据。用 X ∈ R T {P,V,A × d { P,V,A }
}
{ P,V,A }
表示来自这三个模态的输入特征序列,及其维度。
为了将不同模态的特征维度映射到 d,使得跨模态注意力模块的点积(dot-products)可用,为后续
的跨模态交互提供稳定有效的输入特征,数据首先需要通过一个一维时间卷积层对每个模态的输入进
行预处理:
X ̂ = Conv1D ( X ,k ) ∈ R T {P,V,A × d { P,V,A } (6)
}
{P,V,A } {P,V,A } {P,V,A }
式中 k 为针对模态 {P,V,A} 的卷积核大小;
{P,V,A }
为了使序列能够携带时间信息,根据 Vaswani 等 [20] 的方法,为 X ̂ 增加位置嵌入(PE):
{ P,V,A }
Z [ ] 0 = X ̂ + PE (T ,d ) (7)
{P,V,A } {P,V,A } {P,V,A }
式中:PE (T ,d ) ∈ ℝ T { P,V,A } × d { P,V,A } 计算每个位置索引的(固定)嵌入;Z [ 0 ] 为针对不同模态产生的
{ P,V,A } { P,V,A }
低级位置感知特征。
— 1147 —