
Page 34 - 2025年第56卷第9期
P. 34
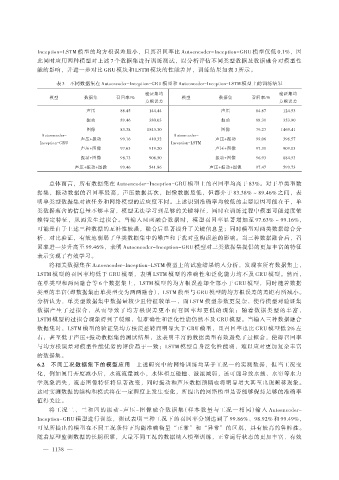
Inception-LSTM 模型的均方根误差最小,且其召回率比 Autoencoder-Inception-GRU 模型仅低 0.1%,因
此同时应用两种模型对上述 7 个数据集进行训练测试,以分析评估不同类型数据及数据融合对模型性
能的影响,并进一步对比 GRU 模块和 LSTM 模块的性能差异,训练结果如表 3 所示。
表 3 不同数据集在 Autoencoder-Inception-GRU 模型和 Autoencoder-Inception-LSTM 模型上的训练结果
验证集均 验证集均
模型 数据集 召回率/% 模型 数据集 召回率/%
方根误差 方根误差
声压 86.45 144.44 声压 84.67 124.53
振动 89.46 380.03 振动 88.31 353.90
图像 83.38 1543.30 图像 79.27 1469.41
Autoencoder- Autoencoder-
声压+振动 99.16 410.32 声压+振动 99.06 396.57
Inception-GRU Inception-LSTM
声压+图像 97.63 919.20 声压+图像 97.31 909.05
振动+图像 98.73 908.50 振动+图像 96.93 884.53
声压+振动+图像 99.46 541.86 声压+振动+图像 97.47 599.73
总体而言,所有数据集在 Autoencoder-Inception-GRU 模型上的召回率均高于 83%。对于单类型数
据集,振动数据的召回率最高,声压数据其次,图像数据最低,但都介于 83.38% ~ 89.46% 之间,表
明单类型数据集对该任务和网络模型的适应度不同。上述识别准确率均较低的主要原因可能在于,单
类数据蕴含的信息量不够丰富,模型无法学习到足够的关键特征,同时在训练过程中模型可能过度依
赖特定特征,从而发生过拟合。当输入两两融合数据时,模型召回率显著增加至 97.63% ~ 99.16%,
可能是由于上述三种数据的互补性较强,融合后显著提升了关键信息量;同时模型对两类数据综合分
析、对比验证,有效地削弱了单类数据集中的噪声和干扰对重构误差的影响。当三种数据融合后,召
回率进一步升高至 99.46%,表明 Autoencoder-Inception-GRU 模型对三类数据集提供的更加丰富的特征
表示实现了有效学习。
将相关数据集在 Autoencoder-Inception-LSTM 模型上的试验结果纳入分析,发现在所有数据集上,
LSTM 模型的召回率均低于 GRU 模型,表明 LSTM 模型的准确性和泛化能力均不及 GRU 模型。然而,
在单类型和两两融合等 6 个数据集上,LSTM 模型的均方根误差却全部小于 GRU 模型,同时随着数据
类型的丰富(即数据集由单类型变为两两融合),LSTM 模型与 GRU 模型的均方根误差的差距有所减小。
分析认为,单类型数据集中数据量较少且特征较单一,而 LSTM 模型参数更复杂,使得模型对验证集
数 据 产 生 了 过 拟 合 , 从 而 导 致 了 均 方 根 误 差 更 小 而 召 回 率 却 更 低 的 现 象 ; 随 着 数 据 类 型 的 丰 富 ,
LSTM 模型的过拟合现象得到了缓解,但准确性和泛化性能仍然不及 GRU 模型。当输入三种数据融合
数据集时,LSTM 模型的验证集均方根误差转而明显大于 GRU 模型,且召回率也比 GRU 模型低 2% 左
右,甚至低于声压+振动数据集的测试结果,这表明丰富的数据类型有效避免了过拟合,使得召回率
与均方根误差对模型性能优劣的评价趋于一致;LSTM 模型自身泛化性能弱,难以应对更加复杂丰富
的数据集。
6.2 不同工况数据集下的模型应用 上述研究中的网络训练均基于工况一的实测数据,但当工况变
化,例如闸门开度减小后,水流流量减小,水体相互碰撞、漩滚减弱,还可能导致水翅、水帘等水力
学现象消失,流态图像特征将显著改变,同时振动和声压数据预期也将明显增大甚至出现频移现象。
这时实测数据的结构和模式将在一定程度上发生变化,所提出的网络模型是否能够保持足够的准确率
值得关注。
将 工 况 二 、 三 和 四 的 振 动 -声 压 -图 像 融 合 数 据 集(样 本 数 量 与 工 况 一 相 同)输 入 Autoencoder-
Inception-GRU 模型进行训练,测试表明三种工况下的召回率分别达到了 99.86%、98.92% 和 99.49%,
可见所提出的模型在不同工况条件下均能准确衡量“正常”和“异常”的区别,具有较高的鲁棒性。
随着原型监测数据的长期积累,大量不同工况的数据纳入模型训练,正常运行状态的更加丰富、有效
— 1138 —