
Page 30 - 2025年第56卷第9期
P. 30
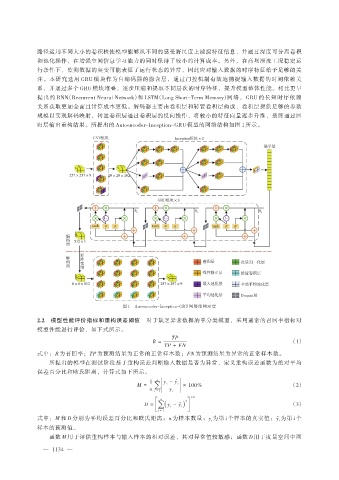
路径运用不同大小的卷积核使模型能够从不同的感受野尺度上捕捉特征信息,并通过深度可分离卷积
和池化操作,在增强空间信息学习能力的同时保持了较小的计算成本。另外,在高坝泄流工况稳定运
行条件下,监测数据的突变可能表征了运行状态的异常,因此应对输入数据的时序特征给予足够的关
注。本研究选用 GRU 模块作为自编码器的隐含层,通过门控机制有效地捕捉输入数据的时间依赖关
系,并通过多个 GRU 模块堆叠,逐步压缩和提取不同层次的时序特征,提升模型整体性能。相比更早
提出的 RNN(Recurrent Neural Network)和 LSTM(Long Short-Term Memory)网络,GRU 的长短时序依赖
关系获取更加全面且计算成本更低。解码器主要由卷积层和转置卷积层构成,卷积层提供足够的参数
规模以实现解码映射,转置卷积层通过卷积层的反向操作,将较小的特征向量逐步升维,最终通过回
归层输出重构结果。所提出的 Autoencoder-Inception-GRU 模型的网络结构如图 1 所示。
图 1 Autoencoder-Inception-GRU 网络结构示意
2.2 模型性能评价指标和重构误差阈值 对于缺乏异常数据的单分类模型,采用通常的召回率指标对
模型性能进行评价,如下式所示。
TP
R = (1)
TP + FN
式中:R 为召回率;TP 为预测结果为正常的正常样本数;FN 为预测结果为异常的正常样本数。
所提出的模型在测试阶段基于重构误差判断输入数据是否为异常,定义重构误差函数为绝对平均
误差百分比和欧氏距离,计算式如下所示。
1
n | | y i - y ̂
M = ∑ | | | i | | | | | × 100% (2)
n i = 1| y i |
é ê ê n 2ù ú ú 1 2
ê
D = ê∑( y i - y ̂ i) ú ú (3)
ëi = 1 û
式中:M 和 D 分别为平均误差百分比和欧氏距离;n 为样本数量;y 为第 i 个样本的真实值;y ̂ 为第 i 个
i
i
样本的预测值。
函数 M 用于评估重构样本与输入样本的相对误差,其对异常值较敏感;函数 D 用于度量空间中两
— 1134 —