
Page 103 - 2021年第52卷第9期
P. 103
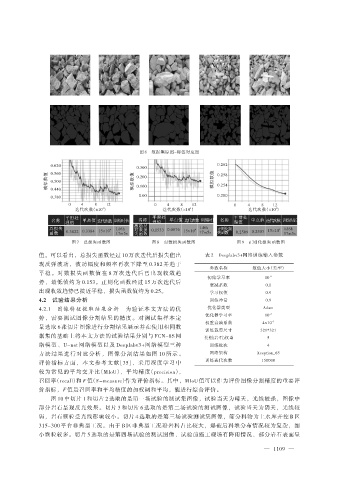
图 6 数据集原图-标签对应图
0.620 0.262
0.300
模拟数值 0.500 模拟数值 0.200 模拟数值 0.258
0.560
0.254
0.100
0.440
0.00 0.280
0.380
0 4 8 12 0 4 8 12 0 4 8 12
迭代次数(×10) 迭代次数(×10) 迭代次数(×10)
4
4
4
平滑处 平滑处 平滑处
名称 单点值 迭代次数 训练时长 名称 理值 单点值 迭代次数 训练时长 名称 单点值 迭代次数 训练时长
理值 理值
总损失 4 1d6h 激励层 4 1d6h 正则化损 15×10 4 1d6h
对数损 0.1533 0.0876
函数 0.3822 0.3384 15×10 17m5s 失函数 15×10 17m5s 失函数 0.2509 0.2507 17m5s
图 7 总损失函数图 图 8 对数损失函数图 图 9 正则化损失函数图
值。可以看出,总损失函数经过 10 万次迭代后损失值出 表 2 Deeplabv3+网络训练输入参数
现反弹波动,波动幅度和频率再次下降至 0.382 并趋于
参数名称 数值大小(类型)
平稳。对数损失函数值在 8 万次迭代后已出现收敛趋
初始学习率 10 -6
势,最低值约为 0.153。正则化函数经过 15 万次迭代后
衰减系数 0.1
出现收敛趋势已接近平稳,损失函数值约为 0.25。 学习权值 0.9
4.2 试验结果分析 训练冲量 0.9
4.2.1 图像特征提取结果分析 为验证本文方法的优 优化器类型 Adam
势,需要测试图像分割结果的精度。对测试集样本定 优化器学习率 10 -3
权重衰减系数 4×10 -5
量选取 6 张切片图像进行分割结果展示并在使用相同数
训练裁剪尺寸 321*321
据集的基础上将本文方法的试验结果分别与 FCN-8S 网 类别(岩石)权重 5
络模型、U-net 网络模型以及 Deeplabv3+网络模型三种 训练批次 4
方法结果进行对比分析,图像分割结果如图 10 所示。 网络架构 Xception_65
评价指标方面,本文参考文献[35],采用深度学习中 训练迭代次数 150000
较为常见的平均交并比(MIoU),平均精度(precision),
召回率(recall)和 F 值(F-measure)作为评价指标。其中,MIoU 值可以作为评价图像分割精度的重要评
价指标,F 值是召回率和平均精度的加权调和平均,能进行综合评价。
图 10 中切片 1 和切片 2 选取的是第一场试验的测试集图像,试验当天为晴天,光线较强,图像中
部分岩石呈现反光效果。切片 3 和切片 6 选取的是第二场试验的测试图像,试验当天为阴天,光线较
弱,岩石颗粒受光线影响较小。切片 4 选取的是第三场试验测试集图像,筛分料物为上水库开挖 B 区
315-300 平台非典型工况。由于 B 区非典型工况玢岩料占比较大,爆破后料堆分布情况较为复杂,细
小颗粒较多。切片 5 选取的是第四场试验的测试图像,试验前施工现场有降雨情况,部分岩石表面呈
— 1109 —