
Page 54 - 2023年第54卷第2期
P. 54
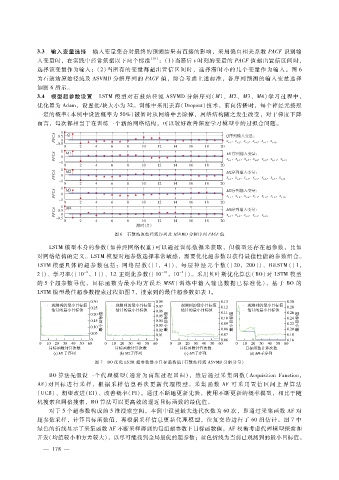
3.3 输入变量选择 输入变量集合对最终的预测结果有直接的影响,采用偏自相关系数 PACF识别输
入变量时,在实践中经常依据以下两个标准 [10] :(1)当滞后 t时刻的变量的 PACF值超出置信区间时,
选择该变量作为输入;( 2)当所有的变量都超出置信区间时,选择滞时小的几个变量作为输入。图 6
为石鼓站原始径流及 ASVMD分解序列的 PACF值,综合考虑上述标准,各序列预测的输入变量选择
如图 6所示。
3.4 模型超参数设置 LSTM 模型对石鼓站径流 ASVMD分解序列(M1、M2、M3、M4)学习过程中,
优化器为 Adam,设置批?块大小为 32。训练中采用丢弃(Dropout)技术,前向传播时,每个神经元按照
一定的概率(本例中设置概率为 50%)被暂时从网络中去除掉,网络结构随之发生改变,对于梯度下降
而言,每次都相当于在训练一个新的网络结构,可以较好改善深度学习模型中的过拟合问题。
图 6 石鼓站原始径流序列及 ASVMD分解序列 PACF值
LSTM模型本身的参数(如神经网络权重)可以通过训练数据来获取,但模型还存在超参数,比如
对网络结构的定义。LSTM模型对超参数选择非常敏感,需要优化超参数以获得最佳性能的参数组合。
LSTM模型具体 的 超 参 数 包 括:网 络 层 数 ([1,4])、每 层 神 经 元 个 数 ([20,200])、BiLSTM([1,
- 10
- 2
- 2
2])、学习率([10 ,1])、L2正则化参数([10 ,10 ])。采用贝叶斯优化算法(BO)对 LSTM 模型
的 5个超参数 寻 优,目标 函数 为最 小均方 误差 MSE(训 练 中 输 入 输 出 数 据 已 标 准 化),基 于 BO的
LSTM模型最佳超参数搜索过程如图 7,搜索到的最佳超参数如表 1。
图 7 BO优化 LSTM超参数最小目标函数值(石鼓站径流 ASVMD分解分量)
BO算法先假设一个代理模型(通常为高斯过程回归),然后通过采集函数(AcquisitionFunction,
AF)对目标 进 行 采 样,根 据 采 样 信 息 再 次 更 新 代 理 模 型。采 集 函 数 AF可 采 用 置 信 区 间 上 界 算 法
(UCB)、期望改进(EI)、改善概率(PI)。通过不断地更新先验,使用不断更新的概率模型,相比于随
机搜索和网格搜索,BO算法可以更高效的逼近目标函数的最优值。
对于 5个超参数构成的 5维搜索空间,本例中设置最大迭代次数为 60次,即通过采集函数 AF对
超参数采样,计算目标函数值,再根据采样信息更新代理模型,往复交替进行了 60组估计。图 7中
绿色的折线显示了采集函数 AF不断采样得到的每组超参数下目标函数值,AF权衡考虑代理模型探索和
开发(均值较小和方差较大),以尽可能找到全局最优的超参数;蓝色折线为当前已观测到的最小目标值。
— 1 7 —
8