
Page 126 - 水利学报2021年第52卷第3期
P. 126
4 深度阈值卷积模型检验与分析
4.1 试验设计 为验证深度阈值卷积模型的准确性,采用筛分试验获取土石料真实级配并采集图
像。本文共进行 18 组不同级配条件下的标准筛分试验,每组土石料翻整 20 次,获得 18×20 张不同的
土石料图像。以其中 16 组图像作为模型训练样本,其余 2 组用于模型验证。经筛分试验获得的 18 组
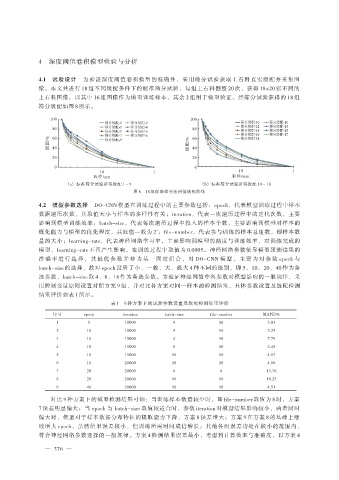
筛分级配如图 8 所示。
100 100
80 80
级配/% 60 级配/% 60
40
40
20 20
0 0
10 1 10 1
粒径/mm 粒径/mm
(a) 标准筛分试验所得级配 1~9 (b) 标准筛分试验所得级配 10~18
图 8 18 组标准筛分法所得级配曲线
4.2 模型参数选择 DO-CNN 模型在训练过程中的主要参数包括:epoch,代表模型训练过程中样本
数据遍历次数,其取值大小与样本的多样性有关;iteration,代表一次遍历过程中的迭代次数,主要
影响到模型训练效率;batch-size,代表每次遍历过程中投入的样本个数,主要影响到模型对样本的
n
概化能力与模型的优化程度,其取值一般为 2 ;file-number,代表参与训练的样本总组数,即样本数
量的大小;learning-rate,代表神经网络学习率,主要影响到模型的精度与训练效率,对训练完成的
模型,learning-rate 不再产生影响,在训练过程中取值为 0.0005。神经网络参数依靠模型预测结果的
准 确 率 进 行 选 择 , 其 最 优 参 数 并 非 为 某 一 固 定 组 合 , 对 DO-CNN 模 型 , 主 要 为 对 参 数 epoch 与
batch-size 的选择,故对 epoch 设置了小、一般、大、极大 4 种不同的级别,即 5、10、20、40 作为备
选参数,batch-size 取 4、8、16 作为备选参数。为验证神经网络中各参数对模型影响的一般规律,采
用控制变量原则设置对照方案 9 组,并对比各方案对同一样本的检测结果,具体参数设置及级配检测
结果评价如表 1 所示。
表 1 9 种方案下的试验参数设置及级配检测结果评价
序号 epoch iteration batch-size file-number MAPE/%
1 5 10000 4 16 3.83
2 10 10000 4 16 3.25
3 10 15000 4 16 7.79
4 10 15000 8 16 2.45
5 10 15000 16 16 4.57
6 10 20000 16 16 4.96
7 20 20000 8 8 13.76
8 20 20000 16 16 10.23
9 40 20000 16 16 4.51
对比 9 种方案下的模型检测结果可知:当训练样本数量较少时,即 file-number 取值为 8 时,方案
7 误差明显偏大;当 epoch 与 batch-size 取值较适合时,参数 iteration 对模型结果影响较小,两者同时
偏大时,模型对于样本数据分布特征的提取能力下降,方案 8 误差增大;方案 9 在方案 8 的基础上继
续增大 epoch,虽然结果误差较小,但训练所需时间成倍增长;其他各组误差均处在较小的范围内,
符合神经网络参数选择的一般规律。方案 4 检测结果误差最小,考虑到计算效率与准确度,以方案 4
— 376 —