
Page 95 - 2024年第55卷第8期
P. 95
果,通过未采用强制学习策略、未添加注意力机制、未使用多任务学习的三个模型分别建立虚拟传感
2
器与基于 TFA - Seq2Seq建立的虚拟传感器进行对比分析。4个模型在训练过程中的 MSE和 R 分别如
图 6和图 7所示,最终虚拟传感器的精度对比和模型训练所需时间对比如表 1所示。
2
2
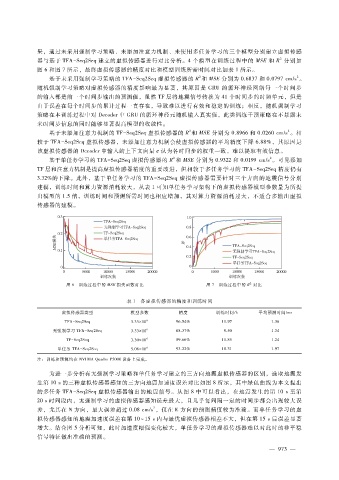
基于未采用强制学习策略的 TFA - Seq2Seq虚拟传感器的 R和 MSE分别为 0.6837和 0.0797cm?s。
随机强制学习策略对虚拟传感器的精度影响最为显著,其原因是 GRU的循环神经网络每一个时间步
的输入都是前一个时间步输出的预测值,虽然 TF层将地震信号转换为 41个时间步的时频单元,但是
由于误差在每个时间步的累计过程一直存在,导致难以进行有效和稳定的训练;相反,随机强制学习
策略在本训练过程中对 Decoder中 GRU的循环神经元随机输入真实值,此类训练干预策略在不暴露未
来时间步信息的同时能够显著提高模型的收敛性。
2
2
基于未添加注意力机制的 TF - Seq2Seq虚拟传感器的 R和 MSE分别为 0.8966和 0.0260cm?s。相
较于 TFA - Seq2Seq虚拟传感器,未添加注意力机制会使虚拟传感器的平均精度下降 6.88%,其原因是
该虚拟传感器的 Decoder中输入的上下文向量 c认为各时间步的权重一致,难以提取有效信息。
2
2
基于单任务学习的 TFA - Seq2Seq虚拟传感器的 R和 MSE分别为 0.9322和 0.0199cm?s。可见添加
TF层和注意力机制是提高虚拟传感器精度的重要改进,但相较于多任务学习的 TFA - Seq2Seq精度仍有
3.32%的下降。此外,基于单任务学习的 TFA - Seq2Seq虚拟传感器需要针对三个方向的地震信号分别
建模,训练时间和算力资源消耗较大,从表 1可知单任务学习架构下的虚拟传感器模型参数量为所提
出模型的 1.5倍,训练时间和预测所需时间也相应增加,其对算力资源消耗过大,不适合多输出虚拟
传感器的建模。
2
图 6 训练过程中的 MSE损失函数对比 图 7 训练过程中的 R 对比
表 1 各虚拟传感器的精度和训练时间
虚拟传感器类型 模型参数 精度 训练时间?h 平均预测时间?ms
TFA - Seq2Seq 3.33 × 10 6 96.54% 11.97 1.36
无强制学习 TFA - Seq2Seq 3.33 × 10 6 68.37% 9.50 1.34
TF - Seq2Seq 3.30 × 10 6 89.66% 11.85 1.24
单任务 TFA - Seq2Seq 5.08 × 10 6 93.22% 18.31 1.97
注:训练和预测均在 NVIDIAQuadroP5000设备上完成。
为进一步分析有无强制学习策略和单任务学习建立的三方向地震虚拟传感器的区别,选取地震发
生第 10s的三种虚拟传感器感知的三方向地震加速度误差对比如图 8所示,其中绿色曲线为本文提出
的多任务 TFA - Seq2Seq虚拟传感器输出的地震信号。从图 8中可以看出,在地震发生的第 10s至第
20s时间段内,无强制学习的虚拟传感器感知误差最大,且几乎每间隔一定的时间步都会出现较大误
2
差,尤其在 N方向,最大误差超过 0.08cm?s,仅在 E方向的预测精度较为准确。而单任务学习的虚
拟传感器感知的地震加速度误差在第 10~15s内与最优虚拟传感器相差不大,但在第 15s后误差显著
增大。结合图 5分析可知,此时加速度幅值变化较大,单任务学习的虚拟传感器难以对此时的非平稳
信号特征做出准确的预测。
— 9 7 3 —