
Page 112 - 2025年第56卷第7期
P. 112
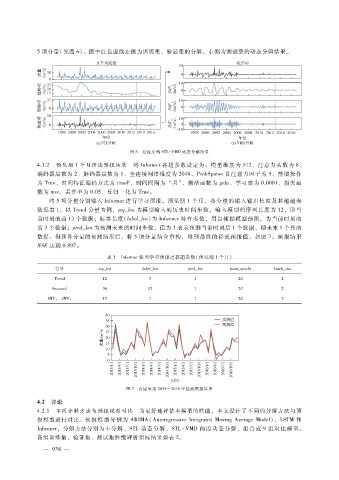
5项分量(见图 6)。图中红色虚线左侧为训练集、验证集的分解,右侧为测试集的动态分解结果。
图 6 径流序列 STL - VMD动态分解结果
4.1.2 预见期 1个月径流预报结果 将 Informer各超参数设定为:模型维度为 512、注意力头数为 8、
编码器层数为 2、解码器层数为 1、全连接网络维度为 2048、ProbSparse自注意力因子为 5、蒸馏操作
为 True、时间特征编码方式为 timeF、时间间隔为 “月”、激活函数为 gelu、学习率为 0.0001、损失函
数为 mse、丢弃率为 0.05、反归一化为 True。
将 5项分量分别输入 Informer进行学习预报。预见期 1个月,各分量的输入输出长度及其他超参
数见表 1。以 Trend分量为例,seq_len为模型输入的历史时间步数,输入模型的序列长度为 12,即当
前时刻的前 12个数据;标签长度(label_len)为 Informer特有参数,用以辅助模型预测,为当前时刻的
前 3个数据;pred_len为预测未来的时间步数,值为 1表示预测当前时刻后 1个数据,即未来 1个月的
数据。得到各分量的预测结果后,将 5项分量结合重构,得到最终的径流预报值,如图 7。预报结果
NSE达到 0.897。
表 1 Informer模型学习预报过程超参数(预见期 1个月)
分量 seq_len label_len pred_len train_epochs batch_size
Trend 12 3 1 20 2
Seasonal 36 12 1 20 2
12 1 1 20 2
IMF 1 —IMF 3
图 7 石匣里站 2013—2016年径流预报结果
4.2 讨论
4.2.1 不同分解方法与预报模型对比 为更好地评估本模型的性能,本文设计了不同的分解方法与预
报模型进行对比。预报模型分别为 ARIMA(AutoregressiveIntegratedMovingAverageModel)、LSTM 和
Informer,分解方法分别为不分解、STL动态分解、STL - VMD两段动态分解,组合成 9组对比模型。
各组训练集、验证集、测试集性能评价指标结果如表 2。
8
— 9 3 —