
Page 113 - 2025年第56卷第7期
P. 113
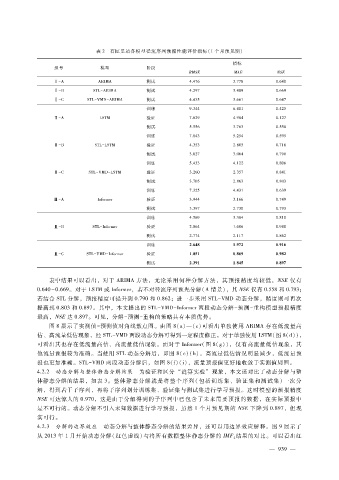
表 2 石匣里站各模型径流序列预报性能评价指标(1个月预见期)
指标
组号 模型 阶段
RMSE MAE NSE
Ⅰ - A ARIMA 测试 4.476 3.778 0.640
Ⅰ - B STL - ARIMA 测试 4.297 3.489 0.669
Ⅰ - C STL - VMD - ARIMA 测试 4.435 3.661 0.647
训练 9.344 6.401 0.425
Ⅱ - A LSTM 验证 7.629 4.984 0.127
测试 5.556 3.763 0.558
训练 7.843 5.254 0.595
Ⅱ - B STL - LSTM 验证 4.353 2.805 0.716
测试 3.827 3.064 0.790
训练 5.433 4.122 0.806
Ⅱ - C STL - VMD - LSTM 验证 3.260 2.357 0.841
测试 3.705 2.863 0.803
训练 7.325 4.431 0.639
Ⅲ - A Informer 验证 3.944 3.166 0.749
测试 3.397 2.730 0.793
训练 4.569 3.384 0.810
Ⅲ - B STL - Informer 验证 2.064 1.606 0.940
测试 2.774 2.117 0.862
训练 2.648 1.972 0.916
Ⅲ - C STL - VMD - Informer 验证 1.051 0.869 0.982
测试 2.391 1.845 0.897
表中结果可以看出,对于 ARIMA方法,无论采用何种分解方法,其预报精度均较低,NSE仅有
0.640~0.669。对于 LSTM或 Informer,若不对径流序列预先分解(A情景),其 NSE仅有 0.558和 0.793;
若结合 STL分解,预报精度可提升到 0.790和 0.862;进一步采用 STL - VMD动态分解,精度则可再次
提高到 0.803和 0.897。其中,本文提出的 STL - VMD - Informer两段动态分解- 预测- 重构模型预报精度
最高,NSE达 0.897。可见,分解- 预测- 重构的策略具有本质优势。
图 8展示了实测值- 预测值对角线散点图。由图 8(a)—(c)可看出单独使用 ARIMA存在低流量高
估、高流量低估现象,经 STL - VMD两段动态分解可得到一定程度修正。对于单独使用 LSTM(图 8(d)),
可看出其也存在低流量高估、高流量低估现象。而对于 Informer(图 8(g)),仅有高流量低估现象,其
他流量预报较为准确。当使用 STL动态分解后,即图 8(e)(h),高流量低估情况明显减少,低流量预
报也更加准确。STL - VMD两段动态分解后,如图 8(f)(i),流量预报值更好地收敛于实测值周围。
4.2.2 动态分解与整体静态分解结果 为验证和区分 “追算实验” 现象,本文还对比了动态分解与整
体静态分解的结果,如表 3。整体静态分解就是将整个序列(包括训练集、验证集和测试集)一次分
解,得到若干子序列,再将子序列划分训练集、验证集与测试集进行学习预报。这时模型的预报精度
NSE可达惊人的 0.970,这是由于分解得到的子序列中已包含了未来需要预报的数据,在实际预报中
是不可行的。动态分解不引入未知数据进行学习预报,虽然 1个月预见期的 NSE下降到 0.897,但现
实可行。
4.2.3 分解的边界效应 动态分解与整体静态分解的结果差异,还可以用边界效应解释。图 9展示了
从 2013年 1月开始动态分解(红色虚线)与将所有数据整体静态分解的 IMF结果的对比。可以看出红
2
— 9 3 9 —