
Page 65 - 2022年第53卷第8期
P. 65
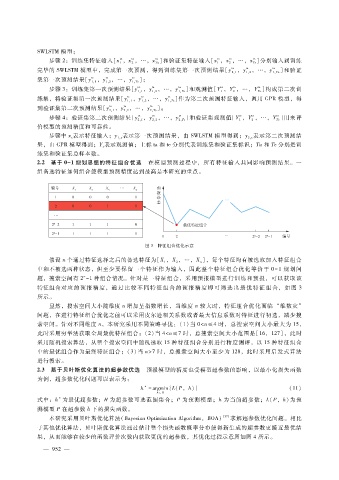
SWLSTM模型;
ta
ta
ta
te
te
te
步骤 2:训练集特征输入[x,x,…,x ]和验证集特征输入[x,x,…,x ]分别输入到训练
1 2 Ta 1 2 Te
ta
ta
ta
完毕的 SWLSTM模型中,完成第一次预测,得到训练集第一次预测结果[y ,y ,…,y ]和验证
1 ,1
1 ,2
1 ,Ta
te
te
te
集第一次预测结果[y ,y ,…,y ];
1,1 1,2 1,Te
ta
ta
ta
ta
ta
ta
步骤 3:训练集第一次预测结果[y ,y ,…,y ]和观测值[Y ,Y ,…,Y ]构成第二次训
1 ,1 1 ,2 1 ,Ta 1 2 Ta
te
te
te
练集,将验证集第一次预测结果[y ,y ,…,y ]作为第二次预测特征输入,调用 GPR模型,得
1 ,Te
1 ,2
1 ,1
te
te
te
到验证集第二次预测结果[ y ,y ,…,y ];
2,2
2,Te
2,1
te
te
te
te
te
te
步骤 4:验证集第二次预测结果[y ,y ,…,y ]和验证集观测值[Y ,Y ,…,Y ]用来评
2,1 2,2 2,Te 1 2 Te
价模型的预测精度和可靠性。
步骤中 x表示特征输入;y 表示第一次预测结果,由 SWLSTM 模型得到;y 表示第二次预测结
2,t
t
1,t
果,由 GPR模型得到;Y表示观测值;上标 ta和 te分别代表训练集和验证集标识;Ta和 Te分别是训
t
练集和验证集总样本数。
2.2 基于 0 - 1规划思想的特征组合优选 在模型预测过程中,所有特征输入共同影响预测结果。一
组备选特征如何组合使模型预测精度达到最高是本研究的重点。
图 3 特征组合优化示意
假设 n个通过特征选择之后的备选特征为[X,X,…,X],每个特征均有被选取加入特征组合
n
1
2
中和不被选两种状态,但至少要保留一个特征作为输入,因此整个特征组合优化等价于 0 - 1规划问
n
题,搜索空间有 2- 1种组合情况。针对某一特征组合,采用预报模型进行训练和预报,可以获取该
特征组合对应 的 预 报 精 度,通 过 比 较 不 同 特 征 组 合 的 预 报 精 度 即 可 筛 选 出 最 优 特 征 组 合,如 图 3
所示。
显然,搜索空间大小随维度 n增加呈指数增长,当维度 n较大时,特征组合优化面临 “维数灾”
问题,在进行特征组合优化之前可以采用皮尔逊相关系数或者最大信息系数对特征进行初选,减少搜
索空间。针对不同维度 n,本研究采用不同策略寻优:(1)当 0<n ≤4时,总搜索空间大小最大为 15,
此时采用穷举法获取全局最优特征组合;(2)当 4<n ≤7时,总搜索空间大小范围是[16,127],此时
采用随机搜索算法,从整个搜索空间中随机选取 15种特征组合分别进行精度测评,以 15种特征组合
中的最优组合作为最终特征组合;( 3)当 n>7时,总搜索空间大小至少为 128,此时采用启发式算法
进行搜索。
2.3 基于贝叶斯优化算法的超参数优选 预报模型的精度也受模型超参数的影响,以最小化损失函数
为例,超参数优化问题可以表示为:
h = argmin {L(P,h)} (11)
h ∈H
式中:h 为最优超参数;H为超参数可选范围集合;P为预测模型;h为当前超参数;L(P,h)为预
测模型 P在超参数 h下的损失函数。
本研究采用贝叶斯优化算法( BayesianOptimizationAlgorithm,BOA) [37] 求解超参数优化问题。相比
于其他优化算法,贝叶斯优化算法通过估计整个损失函数概率分布使得新生成的超参数更接近最优结
果,从而能够在较少的函数评价次数内获取更优的超参数,其优化过程示意图如图 4所示。
2
— 9 5 —