
Page 66 - 2022年第53卷第8期
P. 66
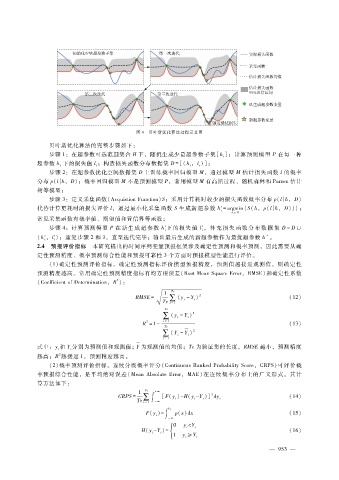
图 4 贝叶斯优化算法过程示意图
贝叶斯优化算法的完整步骤如下:
步骤 1:在超参数可选范围集合 H下,随机生成少量超参数子集[h];计算预测模型 P在每一种
i
超参数 h下的损失值 l;构造损失函数分布数据集 D = [(h,l)];
i i i i
步骤 2:在超参数优化空间数据集 D上训练概率回归模型 M,通过模型 M 估计损失函数 l的概率
分布 p(lh,D);概率回归模型 M不是预测模型 P,常用模型 M有高斯过程、随机森林和 Parzen估计
树等模型;
步骤 3:定义采集函数(AcquistionFunction)S;采用计算耗时较少的损失函数概率分布 p(lh,D)
代替计算更耗时的损失评价 l,通过最小化采集函数 S生成新超参数 h′ = argmin {S(h,p(lh,D))};
i
h ∈H
常见采集函数有概率值、期望值和置信界等函数;
步骤 4:计算预测模型 P在 新生 成超 参数 h′下的损 失 值 l′,补 充 损 失 函 数 分 布 数 据 集 D= D ∪
i i
(h′,l′);重复步骤 2和 3,直至迭代完毕;输出最后生成的新超参数作为最优超参数 h 。
i i
2.4 预报评价指标 本研究提出的时间序列变量预报框架涉及确定性预测和概率预测,因此需要从确
定性预测精度、概率预测综合性能和预报可靠性 3个方面对预报模型性能进行评价。
(1)确定性预测评价指标。确定性预测指标评价模型预报精度,预测值越接近观测值,则确定性
预测精度越高。常用确定性预测精度指标有均方根误差(RootMeanSquareError,RMSE)和确定性系数
2
(CoefficientofDetermination,R):
1 Te
RMSE = ∑ (y- Y) 2 (12)
槡
i
i
Te i =1
Te
∑ (y- Y) 2
i
i
2
R = 1 - i =1 (13)
Te
∑ (Y- Y) 2
i
i
i =1
式中:y和 Y分别为预测值和观测值;Y为观测值的均值;Te为验证集的长度。RMSE越小,预测精度
i
i
2
越高;R越接近 1,预测精度越高。
(2)概率预测评价指标。连续分级概率评分(ContinuousRankedProbabilityScore,CRPS)可评价概
率预报综合性能,是平均绝对误差( MeanAbsoluteError,MAE)在连续概率分布上的广义形式。其计
算方法如下:
1 Te + ∞
2
CRPS = ∑∫ [F(y) - H(y - Y)]dy i (14)
i
i
i
Te i =1 - ∞
y i
i ∫
F(y) = p(x)dx (15)
- ∞
{ 0 y<Y i
i
H(y - Y) = (16)
i
i
1 y ≥Y
i i
— 9 5 3 —