
Page 96 - 2025年第56卷第11期
P. 96
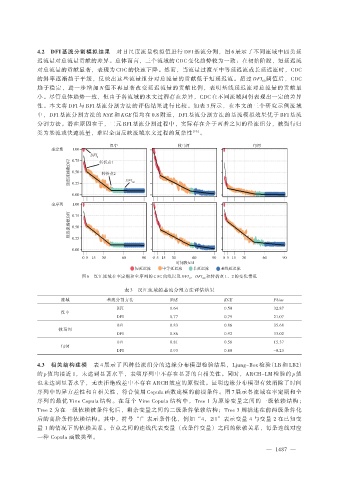
4.2 DFI 基流分割模拟结果 对日尺度流量模拟值进行 DFI 基流分割,图 6 展示了不同流域中四类延
迟流量对总流量贡献的差异。总体而言,三个流域的 CDC 变化趋势较为一致:在初始阶段,短延迟流
对总流量的贡献显著,表现为 CDC 的快速下降。然而,当流量过渡至中等延迟流或长延迟流时,CDC
的斜率逐渐趋于平缓,反映出这些流量组分对总流量的贡献低于短延迟流。超过 DFI 阈值后,CDC
60
趋于稳定,进一步增加 N 值不再显著改变延迟流量的贡献比例,表明基线延迟流对总流量的贡献最
小。尽管总体趋势一致,但由于各流域的水文过程存在差异,CDC 在不同流域间仍表现出一定的差异
性。本文将 DFI 与 BFI 基流分割方法的评估结果进行比较。如表 3 所示,在本文的三个研究示例流域
中,DFI 基流分割方法的 NSE 和 KGE 值均在 0.8 附近,DFI 基流分割方法的基流模拟效果优于 BFI 基流
分割方法。潜在原因在于,二元 BFI 基流分割过程中,实际存在介于两者之间的径流组分,被强行归
类为基流或快速流量,难以全面反映流域水文过程的复杂性 [10] 。
图 6 汉江流域在率定期和全序列的 CDC 曲线以及 DFI 0 ,DFI 60 和转折点 1、2 的变化情况
表 3 汉江流域的基流分割方法评估结果
流域 基流分割方法 NSE KGE Pbias
BFI 0.64 0.50 32.87
汉中
DFI 0.77 0.79 21.07
BFI 0.83 0.86 35.68
牧马河
DFI 0.86 0.92 33.02
BFI 0.81 0.58 15.37
旬河
DFI 0.93 0.80 -0.23
4.3 相关结构建模 表 4 展示了四种径流组分的边缘分布模型检验结果,Ljung-Box 检验(LB 和 LB2)
的 p 值均接近 1,未达到显著水平,表明序列中不存在显著的自相关性。同时,ARCH-LM 检验的 p 值
也未达到显著水平,无法拒绝残差中不存在 ARCH 效应的原假设。证明边缘分布模型有效消除了时间
序列中的异方差性和自相关性,符合使用 Copula 函数建模的前提条件。图 7 展示各流域在率定期和全
序列的最优 Vine Copula 结构。在每个 Vine Copula 结构中,Tree 1 为原始变量之间的一级依赖结构;
Tree 2 为在一级依赖被条件化后,剩余变量之间的二级条件依赖结构;Tree 3 则描述在前两级条件化
后的高阶条件依赖结构。其中,符号“|”表示条件化,例如“4,2|1”表示变量 4 与变量 2 在已知变
量 1 的情况下的依赖关系。节点之间的连线代表变量 (或条件变量) 之间的依赖关系,每条连线对应
一种 Copula 函数类型。
— 1487 —